Kafka는 가장 널리 쓰이는 메세지 큐 솔루션 중 하나이다. 다른 메세지 큐와 마찬가지로, Producer가 메세지를 publish하면 Consumer가 큐를 susbscribe하며 메세지를 가져가게 된다. 다만, 이 사이에 Topic / Partition / Consumer Group과 같은 개념이 등장하게 된다.
How Messages are stored
Kafka Message는 Disk에 저장이 되고, 일정 기간동안 / 또는 일정 용량에 다다를 때까지 저장할 수 있다. 이 값은 각각 토픽의 아래 property들로 설정이 된다.
`retention.ms`: 메세지가 설정된 값 이상으로 오래 되었으면 삭제한다. (default: 604800000 ms = 7일)
`retention.bytes`: 해당 토픽의 각 partition이 가질 수 있는 최대 용량을 설정하고, 초과하면 삭제한다. (default: -1 = unlimited)
Message Order within Topic / Partition
Kafka에서 Producer는 Topic에 메세지를 보내고, 하나의 Topic은 한 개 이상의 Partition으로 나뉘어지게 된다. 이는 topic을 생성하는 시점에 명시할 수 있다.
$ /usr/local/kafka/bin/kakfa-topic.sh \
--zookeeper $LIST_OF_ZK_NODES --topic my-topic --partitions 3 --replication-factor 2 --create
Created topic "my-topic".
Partition은 Topic을 분할한 단위이며, partition이 여러개일 경우 producer가 보낸 메세지의 순서는 보장될 수 없지만, 각 partition 안에서의 메세지를 순서가 보장된다. 아래의 예시를 살펴보자.
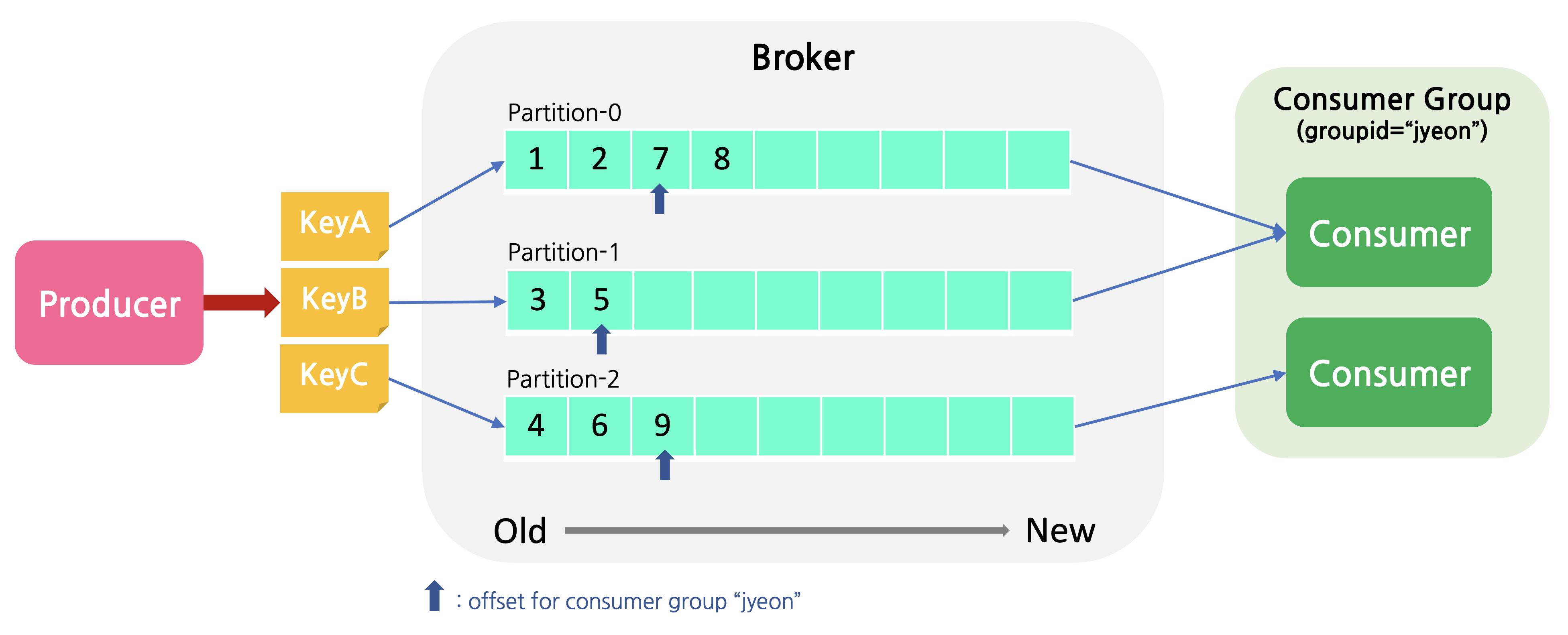
위의 그림에서, Producer는 1,2,3,4,5,6,7,8,9 의 순서로 메세지를 publish하였다. Consumer는 각 partition마다 가지고 있는 offset (마지막으로 읽어들인 record 기록)부터 차례로 메세지를 읽어온다.
하지만 하나의 Consumer가 이 세개의 partition을 모두 subscribe한 경우, 높은 확률로 메세지는 원래 전송된 순서로 오지 않는다. consumer는 세개의 partition을 동시에 바라보기 때문이다. 각 partition에서 한개씩 돌아가면서 메세지를 가져온다고 해도, 1,3,4,2,5,6,7,9,8 의 순서로 메세지가 도착하게 될 것이다.
하지만, 하나의 partition 내에서는 메세지의 순서가 보장된다. 즉, partition 1에서의 1,2,7,8 / partition2에서의 3,5 / partition3에서의 4,6,9는 반드시 이 순서대로 도착하게 된다. 메세지는 key에 따라 각자 다른 partition으로 assign되도록 설정할 수 있으므로, 이는 메세지의 순서가 중요한 경우 유용하게 사용될 수 있다.
예를 들어, 특정 유저의 action이 A -> B -> C의 순서로 발생하고, 이를 Kafka Consumer가 반드시 이 순서로만 subscribe해야 한다면, userId를 partition key로 두어 특정 유저의 action은 모두 같은 partition으로 들어가도록 하여 순서를 보장할 수 있다.
이처럼 메세지의 순서가 중요한 경우, partition의 수를 1로 두거나, 순서가 보장되어야 하는 메세지는 같은 partition에 들어가도록 partition key를 적절히 설정하여야 한다.
Consumer Group
기존의 Message Queue 솔루션에서는 컨슈머가 메시지를 가져가면, 해당 메세지는 큐에서 삭제된다. 즉, 하나의 큐에 대하여 여러 컨슈머가 붙어서 같은 메세지를 컨슈밍할 수 없다. 하지만 Kafka는, 컨슈머가 메세지를 가져가도 큐에서 즉시 삭제되지 않으며, 하나의 토픽에 여러 컨슈머 그룹이 붙어 메세지를 가져갈 수 있다. 또한 각 consumer group마다 해당 topic의 partition에 대한 별도의 offset을 관리하고, group에 컨슈머가 추가/제거 될 때마다 rebalancing을 하여 group 내의 consumer에 partition을 할당하게 된다. 이는 컨슈머의 확장/축소를 용이하게 하고, 하나의 MQ를 컨슈머 별로 다른 용도로 사용할 수 있는 확장성을 제공한다.

위의 그림과 같은 경우, 하나의 토픽에 jyeon 이라는 consumer group과 kim이라는 consumer group 두개가 붙었으며, 파란색 화살표는 jyeon 그룹의 오프셋, 빨간색 화살표는 kim 그룹의 오프셋이다. 즉, 같은 topic에 대해 consuming해도, jyeon group은 각 partition에서 7,5,9를 읽어들일 것이고, kim group은 2,5,6를 읽어들일 것이다. 두 그룹이 모두 메세지를 읽어간 이후에도 message는 사라지지 않은 상태로 얼마간 디스크에 기록된 상태로 남아있으므로, 다른 consumer group이 topic을 처음부터 읽어갈 수도 있고, kim group의 offset을 리셋시켜 맨 처음 / 중간 원하는 offset부터 읽어들일 수도 있다.
Partition - Consumer Assignment
특정 topic을 subscribe하는 consumer는 이 중 하나 이상의 Partition에 할당하여 메세지를 가져오게 된다. 단, 하나의 Partition에는 동일한 Consumer Group에서 반드시 하나의 Consumer만 할당이 된다. (Partition : Consumer = N : 1 관계)
위의 예시에서, 해당 Topic의 partition은 세개이지만 Consumer는 두개밖에 없다. 이 경우, 하나의 consumer에서 두 개의 partition을 담당하게 된다.
반대로, Topic의 partition은 두개이지만, Consumer는 세개인 경우, 하나의 Consumer는 assign된 partition없이 아무 일도 하지 않고 대기만 하게 된다.

이 같은 상황을 방지하기 위하여, partition과 consumer수의 적절한 조절이 필요하다.
Commit / Offset Management
Consumer가 poll()을 호출할 때마다, 컨슈머 그룹은 카프카에 저장되어있는 아직 읽어오지 않은 메세지를 가져온다. 각 topic의 partition마다 어디까지 읽었는지의 정보는 offset이라는 이름으로 broker에 기록이 된다. (offset 정보는 0.8.x까지는 zookeeper에 관리되었고, 0.9부터는 broker에 저장이 된다.) 이 정보는 `offsets.retention.minutes`(default: 1440m=24h)에 명시된 시간동안 저장이 되며, 이 기간이 지나면 consumer offset이 리셋되고, `auto.offset.reset`에 명시된 offset으로 초기화가 된다. (자세한 내용은 jyeonth.tistory.com/3 를 참고)
모든 컨슈머들이 살아있고 제대로 메세지를 polling해가고 있는 동안은 아무런 문제가 없지만, 컨슈머 인스턴스 중 하나가 다운되거나 컨슈머 그룹에 새로운 컨슈머가 들어오게 된다면 컨슈머 그룹 내에서 rebalance가 일어나게 된다. 이 때 각각의 컨슈머는 이전에 처리했던 토픽의 파티션이 아닌, 다른 파티션에 할당되며, 새로 할당된 파티션에 대해 가장 최근에 커밋된 오프셋을 읽어 그 다음부터 메세지를 가져오기 시작한다.
Consumer Health Check & Rebalancing
각 Consumer는 자신이 살아있다는 것(Partition에 대한 소유권을 주장)을 그룹 코디네이터에게 알려주기 위해 `heartbeat.interval.ms`(default: 3s) 주기로 heartbeat를 보낸다. 만약 `session.timeout.ms`(default: 10s) 에 설정된 시간이 지나도록 특정 consumer가 heartbeat를 보내지 않으면, 해당 컨슈머는 종료되었거나 무언가 문제가 생긴 것으로 인지하고 컨슈머 그룹은 rebalance를 시도하게 된다. `session.timeout.ms`는 heartbeat를 보내지 않은 상태에서 consumer가 정상 동작인 상태로 인지되는 시간이다. `session.timeout.ms`가 짧은 경우 장애를 빨리 인지할 수 있지만, 너무 짧게 설정된 경우 Full GC가 오래걸리는 경우 등의 이유로 원치 않은 rebalance가 일어날 수도 있다.
또한, consumer가 heartbeat만 보내고 실제로 topic에서 메세지를 가져가지 않는 경우가 생길 수도 있다. 이 경우, 코디네이터는 해당 consumer를 정상 상태로 인지하기 때문에 consumer는 계속 partition을 점유하고 있지만, 해당 partition에서 메세지는 하나도 consuming이 되지 못하는 상태가 된다. 이러한 경우를 방지하기 위해, `max.poll.interval.ms`(default: 300000ms)를 설정한다. 컨슈머가 heartbeat를 보내더라도, `max.poll.interval.ms` 내에 poll()을 호출하지 않으면 해당 컨슈머를 그룹에서 제외하고 다른 컨슈머에서 해당 파티션에서 메세지를 컨슈밍 할 수 있도록 rebalance를 한다. 어떤 경우 이런 일이 발생할까? 많은 Kafka Library들은 실패한 메세지에 대해 retry 기능을 지원한다. 라이브러리 구현에 따라 다르겠지만, 예를 들어 Spring Cloud Stream Kafka의 경우 maxAtempts (default: 3s)만큼 메세지를 retry하게 되고, 이는 in memory retry이다. 이 retry횟수가 많고 간격이 긴 경우, 해당 메세지를 retry하다가 다음 메세지에 대한 poll()을 호출하지 못하게 된다. 이러한 상황에서 `max.poll.interval.ms`만큼의 시간이 지나면 consumer는 rebalancing되어 다른 consumer가 해당 partition을 처리하게 된다.
How Consumer Offset is Managed
Consumer commit은 자동 커밋 / 수동 커밋 두 가지 방법으로 관리할 수 있다.
자동 커밋
자동 커밋을 사용하려면 컨슈머 옵션 중 enable.auto.commit을 true로 설정해주어야 한다. 이 경우, 컨슈머에서 poll()을 호출할 때 `auto.commit.interval.ms`(default: 5s)이 지났는지를 확인하고, 커밋할 때가 되었으면 가장 마지막 offset을 commit한다. 다만, 주의해야 할 점은 중복 컨슈밍이나 메세지 손실이 발생할 수 있다는 것이다. 예를 들어, `auto.commit.interval.ms`가 5초이고, 이 5초가 지나기 전에 consumer group rebalancing이 일어난 경우를 생각해보자.

위의 그림에서, 커밋된 offset은 2초이고, 8번 offset을 처리하는 도중 consumer session timeout이 발생하던지 consumer가 추가/제거 되는 등의 이유로 rebalance가 되었다고 가정하자. 7번 offset은 이미 처리가 완료되었지만, offset 2번 이후로 offset commit이 되지 않았으므로, reblance 후 해당 partition에 할당된 consumer가 consuming을 시작할 때에는 7번부터 다시 consuming을 하게 된다. 즉, 중복 consuming이 발생할 가능성이 있다는 것이다. `auto.commit.interval.ms`를 줄여서 이런 상황이 발생할 확률을 낮출 수는 있겠지만, 해당 가능성은 항상 존재한다.
메세지가 손실되는 경우를 생각해보자. 자동 커밋의 경우, poll()을 호출하는 시점에 `auto.commit.interval.ms`가 지났으면 마지막 offset을 commit하게 된다. 이 경우, commit은 되어버렸지만 아직 메세지의 처리가 끝나지 못한 상태에서 컨슈머에 장애가 발생하면 해당 메세지는 손실될 수 있다.
수동 커밋
수동 커밋은 메시지 처리가 완전히 완료되기 전까지 메세지를 가져온 것으로 간주되면 안 되는 경우 사용한다. 자동커밋에서 설명한 메세지 손실이 발생할 수 있는 경우를 방지하기 위해, 수동 커밋을 통해 메세지의 처리가 완전히 끝났다고 마킹할 수 있는 시점에 직접 해당 offset을 커밋할 수 있다. 하지만 수동 커밋의 경우에도 마찬가지로, 작업을 처리하다가 에러가 나는 경우 중복이 발생할 수 있다. 예를 들어, message처리 과정이 A -> B -> C -> commit일 때에 B에서 장애가 난 경우, 해당 message는 commit이 되지 않아 재처리가 될 것이기 때문에 A 과정은 중복처리가 될 수 있다. 이와 같은 특성을 고려하여 각 operation을 최대한 idempotent하게 동작할 수 있도록 고려하여 설계해야 한다.
또 한 가지 주의할 점은, consumer 측에서 retry로 처리할 수 없는 메세지가 들어온 경우 (ex. parsing이 불가능한 메세지) 해당 메세지는 절대로 처리될 수 없고, 이 offset이 영원히 커밋되지 못하기 때문에 다음 메세지들이 처리되지 못하고 offset이 잘못된 메세지에 막혀있는 상황이 발생할 수도 있다. 이런 경우 처리할 수 없는 메세지를 다른 토픽으로 보내는 DLQ등을 고려하여 설계해야 한다.
Reference
- www.yes24.com/Product/Goods/59789254?OzSrank=8 - 아주 쉽게 이해할 수 있게 쓰여진 책이라, 강추 :)
카프카, 데이터 플랫폼의 최강자
데이터 플랫폼의 핵심 컴포넌트로 각광받고 있는, 이벤트 기반 비동기 아키텍처를 위한 고가용성 실시간 분산 스트리밍 솔루션 카프카(Kafka)의 모든 것!국내 최대 모바일 플랫폼 회사인 카카오
www.yes24.com
Cloudstream Kafka Found no committed offset for partition 로그 분석. Kafka offset reset 트러블슈팅
Spring Cloudstream Kafka를 사용중, 종종 아래와 같은 INFO 로그를 보게 되었다. Found no committed offset for partition [topic name-partition] 처음에는 INFO 로그이기에 대수롭지 않게 넘겼는데, 이후 cons..
jyeonth.tistory.com
Understanding Spring Cloud Stream Kafka and Spring Retry
I have a Spring Cloud Stream project using the Kafka binder and I'm trying to understand and eventually customize the RetryTemplate used by Cloud Stream. I'm not finding a lot of documentation on ...
stackoverflow.com
'Kafka' 카테고리의 다른 글
| Cloudstream Kafka Found no committed offset for partition 로그 분석. Kafka offset reset 트러블슈팅 (0) | 2020.08.25 |
|---|